Deriving the Cosine Distance for Machine Learning
Cosine distance is used heavily in machine learning and is a very common distance metric alongside the euclidean distance. The biggest advantage of the cosine distance is its robustness against data scale. I.e. if you have various features that have different min and max scales to it, you can directly apply cosine distance and its notion of similarity.
This blog post is to help understand how the cosine distance is derived.
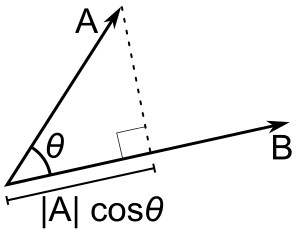
Figure 1: Illustration of the Angular Distance of Theta
In Figure 1 we see vectors A and B in 2 dimensions. In practical situations, you may have many more dimensions but that just means that your vector is longer in length. Now the equation used for cosine distance is typically:

The challenge is how do we get this equation. Note that this equation is very nice since it only depends on dot products and a division. It is extremely efficient to calculate and cos of 90 degrees is 0 and cos of 0 is 1 and cos of 180 is -1, which works perfectly inline with how we see A and B as similar or dissimilar.
It comes from applying vector math on the usual Cosine Rule but with a little trick.
Cosine Rule - c2 = a2 + b2 - 2ab cos theta.
Now lets look at that formula but in vector math notation. Note that vectors are basically each data point with each feature as an independent dimension. E.g. A = (f1,f2,f3...fN)
I couldnt figure out how to add equations in blogpost so forgive the screen shot I had to take just to paste the equations...

Note that ||a-b||^2 is the length of the line between the two points. This is the same as c^2 in the cosine law equation.
Which is what was the definition of the cosine distance we had in the beginning…



